„ Sehr gute Beratung bei der Konzeption unserer App. " Ayse
„ Sehr gute Beratung bei der Konzeption unserer App. " Ayse





Im zweiten Teil unseres Artikels über DNS over HTTPS behandeln wir die Schwachstellen des DNS, wie es ausgenutzt werden kann und wie neue Technologien diese Sicherheitslücken schließen sollen.
Im Normalfall teilt der Resolver dem DNS-Server mit, nach welcher Domain man sucht. Außerdem beinhaltet die Anfrage zumindest einen Teil der eigenen IP-Adresse. Da man sich die fehlenden Teile durch anderweitige Informationen erschließen könnte, hätten Angreifer sämtliche Möglichkeiten, Ihren Rechner ins Visier zunehmen. Es gibt zwei Möglichkeiten, wie Hacker dies nun ausnützen könnten, um sich Ihnen gegenüber einen Vorteil zu verschaffen, das Tracking und das Spoofing.
Es ist also nicht sonderlich schwer Ihre IP-Adresse während einer Anfrage beim DNS-Server auszulesen. Vielleicht denken Sie sich jetzt, dass das ja an sich kein Problem darstellt, Sie haben schließlich nichts zu verbergen? Das mag sein, allerdings wollen Sie sicherlich auch nicht, dass Ihre Daten beziehungsweise Ihr Surfverhalten verkauft werden, oder?
Mit Ihrer IP-Adresse lässt sich mit der Zeit nämlich leicht ein Profil von Ihnen erstellen – was sie suchen, einkaufen, welche Seiten sie häufig besuchen, welche Interessen sie haben. Dadurch lässt sich wunderbar personalisierte Werbung für sie schalten, damit sie noch mehr einkaufen von dem, was sie ohnehin bereits besitzen.
Allerdings hört das nicht bei Werbung auf. Ihre Daten sind äußerst wertvoll für viele Firmen, die unheimlichen Profit daraus schlagen – Google ist nicht umsonst durch den Verkauf solcher Daten milliardenschwer geworden.
Und selbst wenn Sie Ihrem Resolver, den Sie für Ihr privates Netzwerk eingerichtet haben, vertrauen – sobald sie mobil unterwegs sind, ein fremdes WLAN verwenden oder sich in einem Hotel einloggen, verwenden Sie möglicherweise einen anderen Resolver, der dann eben nicht mehr vertrauenswürdig ist. Und wer weiß schon, wie dieser Resolver mit denen von Ihnen gesammelten Daten umgeht?
Beim Spoofing klinkt sich jemand in Ihre Verbindung ein und verändert die Antwort, die vom DNS Server an Ihren Browser zurückgesendet wird. Anstatt Ihnen also die IP-Adresse der Seite, die Sie besuchen wollen, zu geben, wird Ihnen eine falsche Adresse zugesteckt. Auf diese Weise kann eine Seite Sie davon abhalten eine bestimmte Seite zu besuchen.
Warum sollte eine Seite tun? Nehmen wir folgendes Beispiel: Sie stehen in einem Laden und wollen die Preise im Regal mit denen im Internet bei einem anderen Anbieter vergleichen. Sollten Sie nun im WLAN-Netzwerk des Ladens sein, in dem Sie gerade stehen, verwenden Sie auch den Resolver, der in diesem Netzwerk eingerichtet ist. Und dem Geschäft wäre sicherlich daran gelegen, dass sie keine günstigeren Preise finden, als die, die sie im Laden vor sich haben, oder?
Und schon haben Sie ein Motiv dafür, eine andere, verfälschte Internetseite anzeigen zu lassen oder die gesuchten Vergleichsportale einfach vollständig zu blockieren.
Netzwerke kommen im Normalfall ohne Probleme mit den oben genannten Praktiken davon, da die wenigsten Nutzer überhaupt davon wissen, geschweige denn sich damit auskennen und Gegenmaßnahmen ergreifen könnten. Und vielen wäre es wohl auch ziemlich egal, selbst wenn sie davon wüssten. Doch selbst für User, die sich mit der Materie auskennen, ist es schwierig, dafür zu sorgen, dass mit ihren Daten kein Schindluder getrieben wird.
Nun gibt es neben Browsern, die zu Firmen mit wirtschaftlichen Interessen gehören, auch Initiativen, die OpenSource und non-profit arbeiten. Die Mozilla Foundation beispielsweise arbeitet an Lösungen, die diese Sicherheitslücken schließen.
Der Mozilla Firefox nutzt nun also standardmäßig den sogenannten Trusted Recursive Resolver (TRR), der in hohem Maße darauf ausgelegt ist, keine verwertbaren personenbezogenen Daten der Nutzer weiterzugeben oder zu speichern. So werden sämtliche für die Suchanfragen verwendeten Informationen innerhalb von 24 Stunden wieder gelöscht. Der OpenSource-Browser kann damit den vom Netzwerk vorgegebenen Resolver ignorieren und eine sichere Variante verwenden.
Neben dem Verwenden eines auf Privatsphäre getrimmten Resolvers sorgt die Verschlüsselung der Suchanfragen eine große Rolle. So wird mittlerweile standardmäßig (und von allen aktuellen Browsern) das HTTPS-Protokoll angewandt.
Weiterhin sendet der TRR von Firefox nicht die gesamte angefragte Domain, sondern immer nur den Teil der Adresse, der für den Server, der gerade kontaktiert wird, relevant ist. Außerdem wird die Anfrage von dem von Firefox genutzten Dienst Cloudflare nicht weitergeleitet, sondern die Anfrage wird von einer dem Dienst eigenen IP-Adresse gesendet.
So wird nur ein Minimum an Informationen versandt, sodass zumindest der Aufwand, Rückschlüsse auf die Zieladresse oder die IP-Adresse zu erhalten, bei weitem größer wird.
Auf die oben genannte Weise wird also die Zahl derjenigen, die Ihre Daten abgreifen können, um ein Vielfaches reduziert. Allerdings sind Ihre Verbindungen damit noch nicht vollständig sicher.
Nachdem Sie über den DNS-Server herausgefunden haben, wo Sie das Ziel Ihrer Suche finden können, müssen Sie sich erst noch mit dem jeweiligen Server verbinden. Um dies zu tun, schickt der Browser eine Anfrage an diesen Server – und diese Anfrage ist nicht verschlüsselt. Hier kann sich also sehr wohl jemand einklinken und mithorchen, welche Seiten Sie besuchen.
Sobald Sie allerdings mit dem jeweiligen Server verbunden sind, ist alles verschlüsselt. Praktischerweise gilt das auch für alle Seiten, die auf diesem Server gehostet werden. Schlagen Sie beispielsweise einen weiteren Wikipediaartikel nach, der auf demselben Server gespeichert ist, so wird keine vollständige Anfrage an den Server geschickt, sondern die bestehende (verschlüsselte) Verbindung wird weiterhin verwendet.
Da das DNS eines der ältesten Grundbausteine des Internets ist und an dessen Struktur sich nicht viel verändert hat was die Privatsphäre oder Datensicherheit verbessert, ist es an der Zeit, dies in Angriff zu nehmen. Gemeinnützige Initiativen wie Mozilla unterstützen diese Weiterentwicklung und bringen sie bewusst voran.
Wer an Mozillas Studie zur Weiterentwicklung des oben beschriebenen TRR mitwirken möchte, kann sich hierfür die in Entwicklung befindende Firefox Nightly auf der Mozilla-Homepage herunterladen.

Wie würden Sie einem Kollegen erklären, was Ihr Browser im Hintergrund anstellt, wenn Sie ihn anweisen, eine Internetseite aufzurufen? Überfragt? Dann hilft Ihnen der folgende Artikel weiter. Hier erklären wir, was DNS und HTTPS sind und wie sie zusammenspielen.
Mit der zunehmenden Digitalisierung und der Omnipräsenz des Internets im alltäglichen Leben steigt auch das Verlangen nach der Gewährleistung von Privatsphäre und Datenschutz. Durch neue Datenschutzgesetze (zum Beispiel die DSGVO) soll diesem Verlangen Sorge getragen werden. Aber auch Softwareunternehmen und Organisationen arbeiten zunehmend an Sicherheitslösungen – nicht nur aus Gründen des Datenschutzes, sondern auch aus eigenem und wirtschaftlichem Interesse natürlich. HTTP steht dabei für Hypertext Transfer Protocol.
Kommen wir auf unsere Ausgangsfrage zurück: Was passiert, wenn Sie eine Internetseite aufrufen? Eine einfache Antwort wäre, dass der Browser erst eine Anfrage an den Server verschickt, dass er die Seite gerne anzeigen würde und der Server dann eine Antwort verschickt, in der die Datei steckt. Das nennt man dann HTTP und dürfte Ihnen bekannt vorkommen – etwas ähnliches steht in der Adresszeile Ihres Browsers ganz am Anfang.
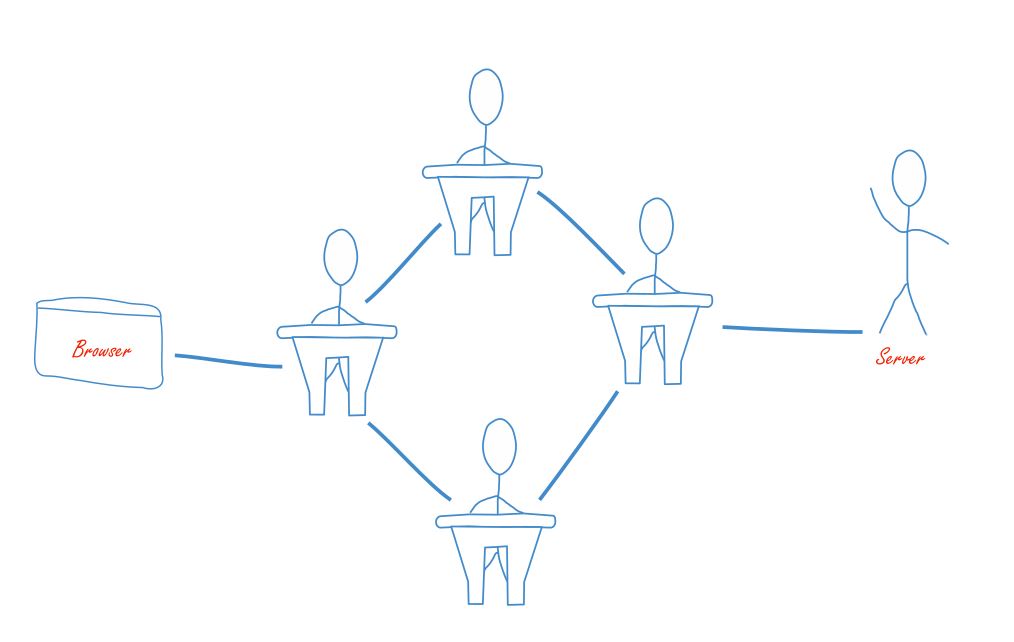
Das Problem bei der Sache ist: So einfach funktioniert das Internet dann doch nicht. Denn normalerweise steht der Server, den Ihr Browser kontaktiert nicht gleich bei Ihnen ums Eck, sondern gerne auch mal auf einem völlig anderen Kontinent. Und dorthin gibt es von Ihrem PC aus auch keine direkte Kabelverbindung. Also müssen hierfür Mittelsmänner herhalten, die erst die Anfrage an den Server weitergeben und das gleiche dann auch mit der Antwort machen.
Diese Prozedur ist gut mit einem Klassenzimmer vergleichbar. Ein Schüler schreibt einen Brief und den Namen des Adressaten außen drauf, um ihn dann über mehrere Stationen an einen weiter entfernten Mitschüler zu schicken. Das Problem dabei ist, dass vielleicht nicht jeder der Mitschüler, durch deren Hände der Brief wandert, auch vertrauenswürdig sind und nicht neugierig den Inhalt des Briefes lesen.
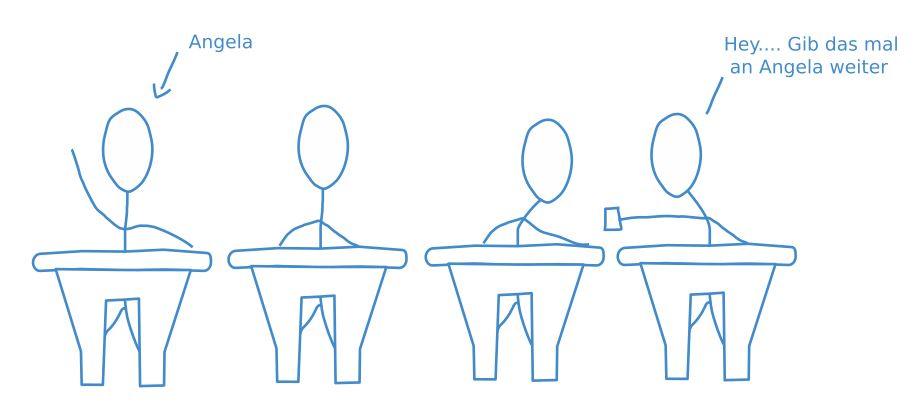
Um diesen neugierigen Mitschülern entgegen zu wirken, wurde HTTP weiterentwickelt zu HTTPS – und das ist das, was tatsächlich in der Adresszeile Ihres Browsers steht. Das angehängte S steht für secure, also sicher. Man kann sich diese Weiterentwicklung als Brief mit Vorhängeschloss vorstellen, zu dem nur der Sender und der Empfänger den Schlüssel haben, die einzelnen Mittelsmänner (oder Schüler) aber eben nicht.
Dieses virtuelle Vorhängeschloss behebt schon einige Sicherheitslücken. Absolut sicher ist es aber auch nicht. Zum einen muss der Sender als ersten Schritt den Server kontaktieren, um eine Verschlüsselung aufbauen zu können. Diese erste Kontaktaufnahme ist aber logischerweise noch nicht verschlüsselt, da der Server sonst nichts damit anfangen könnte.
Die zweite Lücke, an der die Daten noch immer ungeschützt sind, besteht am DNS.
Die DNS hat in diesem Fall nichts mit Genetik zu tun, sondern steht für Domain Name System. Wie in unserem Vergleich mit dem Klassenzimmer muss auf der Anfrage des Nutzers quasi der Name des Empfängers stehen. Da der Server aber mit dem Klarnamen der Homepage nicht wirklich etwas anfangen kann, muss dieser so gestaltet sein, dass der Server versteht, was zu tun ist. Dies wird über das DNS erreicht.
Im Prinzip wird über das DNS jeder Internetseite nur eine IP-Adresse zugeordnet, mit der sie eindeutig zu erreichen ist. Damit der Browser weiß, wie er das tun muss, müsste er über eine sehr lange Liste verfügen, in der alle verfügbaren Webseiten eingetragen sind, ähnlich einem Telefonbuch. Allerdings hätte man damit das Problem, dass bei der enormen Menge an neu angelegten Webseiten diese Liste gar nicht schnell genug aktualisiert werden könnte. Also unterteilt man sie einfach in eine Reihe weitere Listen.
Es entsteht also quasi eine Datenbank mit vielen Unterlisten, die separat verwaltet und aktualisiert werden können. Schauen wir uns beispielsweise folgende Internetadresse an:
de.wikipedia.org
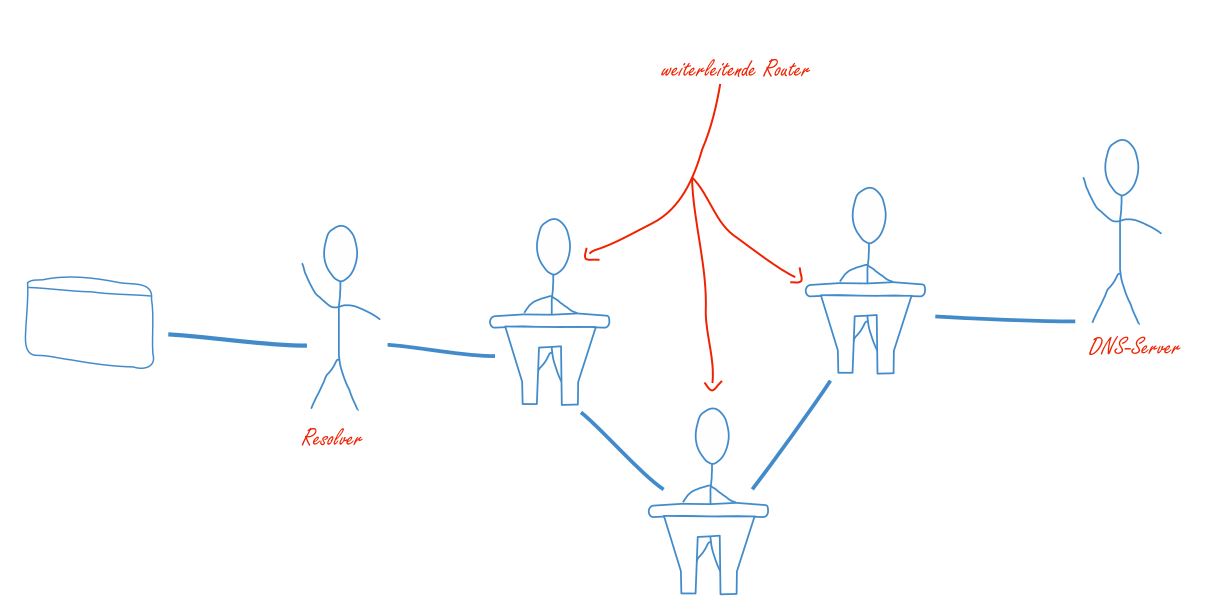
Die Punkte in der Adresse separieren die einzelnen Teillisten voneinander. Dabei geht der Browser (beziehungsweise der sogenannte Resolver) von hinten nach vorne vor. Als erstes wird also ein Server (der Root DNS Server) kontaktiert, der dann einen Server mit der Liste für die top-level Domains zurückgibt. In unserem Fall bräuchten wir einen Server, der mehr über .org Domains weiß.
Auf diesem Server finden wir dann wiederum alle Informationen über die second level domains, die unter .org zu finden sind. Für uns wäre das also der Namensserver für Wikipedia. Dieser Server kann uns dann weiterverbinden auf den zuständigen Server für die subdomains von Wikipedia. Hier bekommen wir nun also die Information, unter welche IP-Adresse die HTML-Datei der deutschen Wikipedia-Seite zu finden ist. Diese Adresse schickt der Resolver dann zurück an Ihren Browser.
Der Resolver ist allerdings nicht immer derselbe. Es gibt zwei Möglichkeiten, wie entschieden wird, welcher Resolver verwendet werden soll. Entweder der Benutzer stell ganz konkret einen Resolver ein, sodass sein Computer immer diesen einen verwendet oder er belässt die Voreinstellungen, sodass der Resolver vom System ausgesucht wird.
Im zweiten Teil unseres Artikels über DNS über HTTPS (DoH) lesen Sie mehr über die Sicherheitsrisiken beim Surfen im Internet, wie diese geschlossen werden können und was Sie als Nutzer aktiv für Ihre Privatsphäre tun können.
Haben Sie Probleme mit dem Internet oder Sicherheitsbedenken beim Surfen? Unsere IT-Spezialisten aus München helfen Ihnen gerne bei allen Ihren PC-Problemen weiter!
Nehmen Sie noch heute mit uns Kontakt auf!
Wir freuen uns auf Ihre Anfrage!

Wer im Internet verkehrt, arbeitet (meist unbewusst) mit Hyperlinks. Sie finden sich auf jeder Webseite und werden millionenfach verschickt, um Freunde auf Bilder, YouTube-Videos oder Homepages aufmerksam zu machen. Was genau so ein Hyperlink ist, erklären wir in diesem Artikel.
Was ist ein Hyperlink und was macht er?
Ursprünglich ist ein Hyperlink (oder kurz Link) nichts anderes als ein Verweis an eine andere Stelle als die, an der der Hyperlink aufgerufen wird. Dabei entstammt dieses Prinzip dem Buchdruck: In wissenschaftlichen Abhandlungen wird seit jeher mit Querverweisen und Fußnoten gearbeitet, um auf bereits erschienene Arbeiten zu referenzieren und seine Argumentationen zu belegen. Dieses Konzept wurde auch für das Internet übernommen und zum Hyperlink ausgebaut, wo es mittlerweile ein essentieller Bestandteil des World Wide Web geworden ist.
Ein Hyperlink besteht aus zwei Komponenten: dem für den Nutzer sichtbaren und den unsichtbaren Teil. Der sichtbare Part ist eine im Browser angezeigte Schaltfläche, die bei einer Interaktion die Verlinkung auslöst. Dieser muss dabei nicht den eigentlichen Link darstellen, sondern kann von einem Bild oder einem Satz dargestellt werden. Dies dient dazu, den Lesefluss nicht zu unterbrechen. Meist wird dieser sichtbare Teil unterstrichen formatiert, um ihn als Link zu markieren.
Der unsichtbare Teil enthält schließlich alle technischen Informationen, die der Browser braucht, um die Verlinkung durchzuführen. Neben der Webadresse sind das Metadaten, die zum Beispiel definieren, ob ein Tooltip angezeigt werden soll, wenn man mit der Maus über den Link fährt oder ob die verlinkte Seite in einem separaten Fenster aufgerufen werden soll.
Dieser Link: https://www.esenbyte.de/news/item/122-welche-browser-gibt-es-und-welches-sind-die-besten verweist beispielsweise auf unseren Artikel über Webbrowser. Hier wird der gesamte Link angezeigt, was dem Lesefluss nicht unbedingt zuträglich ist. Alternativ sehen Sie bei diesem Link [LINK Esenbyte-Seite], wie es aussieht, wenn eine unsichtbare Komponente mit eingebaut wurde. Der eigentliche Hyperlink wird hinter dem sichtbaren Text versteckt.
Und worauf verweist nun ein Hyperlink?
Allgemein gesprochen verweist ein Hyperlink lediglich auf ein anderes Dokument im Internet oder auf eine andere Stelle im selben Dokument. Ersteres findet beispielsweise häufig in digitalen Lexikoneinträgen (wie auf Wikipedia) Verwendung, wenn auf einen anderen Artikel innerhalb des Lexikons verwiesen werden soll. Des Weiteren finden sich oft Hyperlinks am Ende eines Webdokuments, beispielsweise am Ende eines Blogbeitrages, von wo aus der Leser wieder an den Anfang der Seite gelangt.
Neben der Verlinkung auf eine andere Internetseite kann ein Hyperlink alternativ auf andere Medien wie Bilder oder Videos verweisen. Daneben kann dadurch aber auch direkt ein Download einer beliebigen Datei ausgeführt werden.
In allen gängigen Browsern Google Chrome oder Mozilla Firefox wird der Link einer Seite (oder eines Mediums wie Bild oder Video) oben in der Mitte des Fensters angezeigt. Man nennt diese Webseiten-Adresse auch URL (Uniform Ressource Locator). Er kann kopiert und beispielsweise in Office-Dokumente als Hyperlink eingebunden oder über soziale Netzwerke geteilt werden.

Worauf sollte man beim Umgang mit Hyperlinks achten?
Da man oft nicht erkennen kann, worauf ein Link genau referenziert (Stichwort sichtbare und unsichtbare Bestandteile), sind Verlinkungen im Internet generell mit Vorsicht zu gebrauchen. Generell sollte man nur auf URLs vertrauen, die in der Adresszeile HTTPS:// stehen haben. Dies stellt sicher, dass eine Verschlüsselung bei der Datenübertragung zwischen Browser und Server eingesetzt wird.
Außerdem sollte man, wenn möglich nur Links aus Quellen anklicken, die einem bekannt sind und denen man auch vertraut, um Phishing oder anderen kriminellen Vorgängen aus dem Weg zu gehen.
Unter dem Begriff Hotlinking versteht man das Einbetten eines Links in eine Webseite, wobei der verlinkte Inhalt nicht auf der Webseite direkt gespeichert wird, sondern von einer fremden Homepage stammt. Die Datenlast wird damit nicht von der eigenen Homepage getragen, sondern ausgelagert. Bestes Beispiel hierfür sind eingebettete YouTube-Videos, die man direkt von der Internetseite aus aufrufen kann, ohne erst auf die eigentliche YouTube-Seite zu wechseln. YouTube erlaubt diese Vorgehensweise als Teil ihres Geschäftsmodell, während andere Anbieter diese Praktiken untersagen. Bei der Einbettung von externen Links auf dem eigenen Blog oder Webseite sollte also vorher abgeklärt werden, wie der Inhaber der verlinkten Medien diesbezüglich verfährt.
Manchmal kann es nützlich sein, URLs zu kürzen, da sie in manchen Fällen sehr lang ausfallen können. Hierfür kann man verschiedene Internetseiten verwenden, die einem einen persönlichen, gekürzten Link erstellen. Hierfür gibt es auch Browser-Addons, beispielsweise für Google Chrome oder Mozilla Firefox. Über die Verwendung solcher Addons folgt demnächst ein weiterer Artikel.
Fazit
Hyperlinks sind das Rückgrat des modernen Internets. Neben den offensichtlichen Vorteilen ihrer Verwendung sollte man allerdings nicht zu sorglos mit ihnen umgehen, speziell, wenn man ihre Herkunft nicht kennt oder der Quelle nicht vertraut. Dann sollte man lieber die Finger von ihnen lassen.
Vielleicht suchen Sie einen App-Dienstleister der Ihnen eine App für eine Sammlung von Links oder mit Webviews programmiert? Alls App Agentur in München entwickeln wir ihre individuelle App für mobile Endgeräte.
Rufen Sie uns einfach unter 0176 75191818 an oder senden Sie uns eine E-Mail an Diese E-Mail-Adresse ist vor Spambots geschützt! Zur Anzeige muss JavaScript eingeschaltet sein! . Gerne unterbreiten wir Ihnen ein individuelles Angebot.
|
App Anfrage 0176 75 19 18 18
Kostenfreie Erstberatung |

